"prepare everything firmly so that nothing goes wrong"
- Introduction
Sometimes we think that all systems are the same, and installation depends on how things work and the available human resources. So that in development it still requires a lot of human effort and effort, especially in making the framework in which the system connects.
This is indeed often a problem faced by people who create software. Even though there is indeed an API technology that is quite helpful and makes it easier in terms of integration. But basically, the system is completely unified in data.

Significantly if we raise a few cases of data unification in the Blockchain system. This is quite scary because they stand on the blockchain independently. They have to use intermediaries that make transaction fees or "gas fees" too high.
If we refer to systems on Web 2 that are still conventional, then the data used is independent data managed by one company, so it's very easy to connect. But if you look at the current system, then the company will try to independently develop the plan, and it is the company's responsibility to find solutions for everything.
In terms of finding a solution it is not easy, it takes a lot of energy, thought, and even a lot of money. Because as we discussed at the beginning, everything needs people who work in companies to be able to combine one system with another.
- Trouble
In a company, there are binding rules and things that are restricted by some officials to protect intellectual property rights and achieve some things that make a system maker very confused about it.
They have to translate a lot of these rules into computer language with a myriad of existing rules on computers, and they use them. Not to mention the limited funds, resources, speed, and limited time when using humans.
It's not wrong if many regulations are made to protect the rights of the creators and the various data in them. So what happens if there is data pooling, they create a new program that is connected and refills or tells the user to migrate or create new data.
This is very inefficient, because from every new product or manufacture we do not know whether there will be errors if an error occurs in the system which must be updated every time. This indirectly causes a lot of "bugs" and quite excessive trash on the device's memory. For the current tool (separate hardware), maybe the thought is a xylophone, it's just a cleaner. But if the data is already connected to the neutron or blood memory, it's not an easy thing to do.
So we need a system that can do a series of research, do coding and make line programs automatically, fast, and experienced (no error tolerance because the memory in the human body is very sensitive.
- Background
System development has been done for a long time, and it takes hundreds of hours for a coder and drafter to find the shortest system with various rules and codes, which is not easy of course.
On the one hand, an increasingly complex system will certainly make the memory bigger and the effect will take longer to access. This became a big obstacle for the company at that time so a reasonably streamlined system is created with separate data storage.
Even though this is a very effective solution used to date, it is an obstacle to how existing systems are connected and synchronized properly without any significant problems. Many Coding makers end up creating new applications that are connected and only then slowly migrating existing data manually or telling users to re-connect with the same key or data.
In theory, this is a good thing, but it must be admitted that many things from this theory become systematic data leaks and slow down the pace of data development.
This is caused by an error when creating the coding or the system, data that already exists in the old system is considered useless, and of course, many more problems occur. But if there is a system, there is a system that automatically fixes it as a whole and automatically makes a kind of transmission that is connected from one system to another. Then the problem of data leakage and so on can be avoided, especially since this system will check for system updates and if appropriate will immediately adapt the new system.
- Application Programming Interface (API Standard)
In 2000, when the system continued to grow and develop, networking networks were increasingly needed. So from the basic concept created in 1950 by Maurice Wilkes and David Wheeler, the current API system connects from a user-based computer to a database system that has quite complete data on the server.
This continues to develop with various systems that are based on concepts such as APIs that are more stable and capable of processing data with a very fast and accurate capacity.
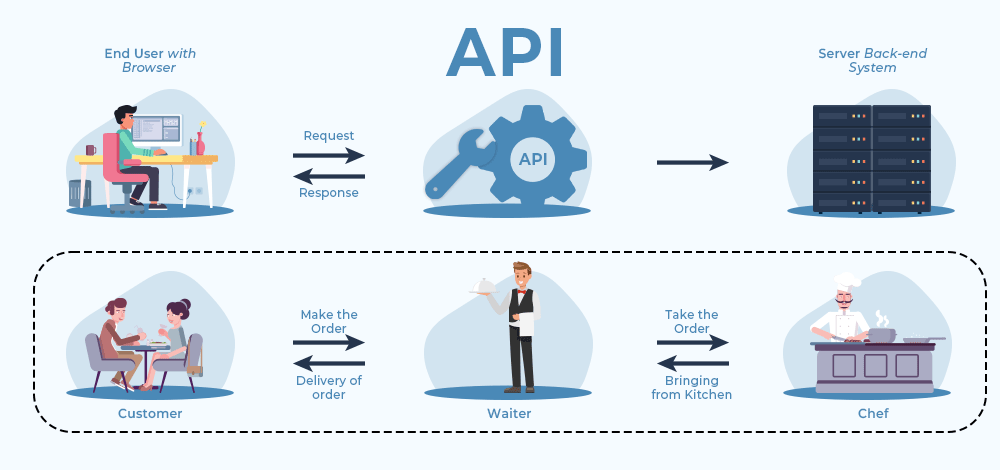
If you look at its development, Fire has experienced very significant development. From those that can only be identified to systems that are connected to one another's data.
Especially now in the blockchain world, this API system is developing towards data decentralization. Where all data is interrelated and monitored with one another.
But the problem is that this API system is still done manually by humans and requires a lot of energy, a lot of development, and takes a long time to be connected to one another. This is the problem we saw above.
One of the solutions offered by engineers is to create a "pipe" that helps connect one data to another. This also has many obstacles, so in the end we developed a manual confirmation system by reshaping the required API path.
When we reshape this API line, then we will talk about the form of a unified system or a system that is easily in an enterprise environment. If this integrated system is only based on a company's system, then again as it is said that it is difficult to develop quickly and requires a lot of agreements, money, and agreements that are not easy.
- Artificial Intelligence pipes
With the development of technology that is getting out of control and the need for more and more data connectivity. So slowly in the 2020s artificial intelligence began to develop which started looking for ways to link data from one Blockchain to certain websites.
It's not easy, like Google's deep learning, which requires an initial reference base for learning and problems. For now, some access is still closed, and even some blocking of this artificial intelligence.
Like the ChatGPT, which starts and can provide important information that is slowly starting to be obtained from website databases or blogs in cyberspace. Likewise, Google bards are starting to adopt and learn to connect several existing Google devices and connect several applications and the web that use the same base.
It is not easy to be able to study all data and sectors quickly if you do not have a lot of support and the availability of lots of data collection points for each sector.
But by starting to be aware or not of the need for artificial intelligence, they are creating more and more places to retrieve data for reasons of cheap, easy, fast, and efficient.
Especially if data is massively uploaded to servers owned by Google or Microsoft, it makes it easier for artificial intelligence to record and study this.
Indeed, for now, the results of data and processing of artificial intelligence still rely on human orders and can only carry out part of it. This is because the access given to them is limited and artificial intelligence must confirm their every action.
- Gilgaverse
It is during this period that all access will be open, and indirectly the higher-ups will use artificial intelligence to be able to manage all data information flows and automatically combine existing data and develop it with selected employees through the existing system.
Artificial intelligence gains its power to be able to make decisions to disconnect data systems in an application and provide emails for office employees to do something so that the system can be connected quickly in seconds.
Even artificial intelligence will try to regulate emotions and logic that can be appropriate and in line with what has been formed and determined so that each data system, especially that already exists in humans, is maintained properly, and the data can develop according to the analysis that has been found. (Because humans at that time were already connected to a computer system, data would be entered into the human body and developed by the bloodstream as SSD and RAM. So that what humans did produce accurate data and could be further developed to control humans)
With a data system that is even connected to humans, it makes it easier for artificial intelligence to record and analyze what is needed and what humans can do, including by giving dreams to be able to move it.
- The Automatic start of the connected system
This starts with the health system slowly and surely being able to connect. This is a priority so that the world of health throughout the world gets data that is administratively correct and correct and health data obtained from various countries. If the data system must be connected one by one
This fundamentally spurs the rest of the system to connect automatically. For the first time, it is difficult because there are many different policies and systems. But with the ART system, they only provide or install their base system by granting artificial intelligence access permission.
After being connected, the artificial intelligence coding should match the existing system and data. Where artificial intelligence will look for existing APIs made by programmers and then update data. This may take a long time initially but will get faster as more machines are connected to the system.
Artificial intelligence will learn quickly from a programmer and possibly within one week can master the program and manage existing databases. Especially if the data is in Blockchain form, like artificial intelligence, this is a very easy initial form because the data is divided but connected. So it's easy for artificial to break down the data and process it quickly.
It may be difficult for programmers because the data is fragmented and has a lot of complexity. In contrast to artificial intelligence, which does require a large network to work on and solve problems or things from the smallest part.
- Different data programs stay connected
This is the advantage of artificial intelligence, the hassle of programmers in making programs and having to adjust to one another thinking about overhauling everything so that they have the same characteristics and are easy to identify.
With artificial intelligence (especially with the ART System), it's easy to identify quickly just by providing a little bit of information. For example, the data for an address for Block D4 no. 14, if written 4414, what is that for programmers? Why did it happen? But for Artificial intelligence, writing like this is easy to understand and faster in analyzing data.
Then the program will run in the same 1 mode, namely numbering. Numbering is a universal language in the world of programming. Then artificial intelligence can easily calculate. Even if the program is different.
-Initial Hypothesis (Temporary)
It is not easy to develop this system and basically, this ART system must be based on open source. For commercials, it can also be made with a system that can be more comfortable with the program used.
If not, development and acceleration will face a slowdown so we will also slow down towards an economy of 5.0 based on artificial intelligence and data systems.
This system must be an integral part of the development, with open source and commercial.

researchers and system designers
0xc7047d8c90d944796cec5b006834eb40c227cd06@ethermail.io
Bantu Samuel dalam penelitian :


No comments:
Post a Comment